Відкриті дані, як засіб контролю якості держави. Вибори
23 Серпня 2021 | Олександр Рундель
Категорія: Я так думаю (особистий блог)
Теги: відкриті дані, вибори, статистика
Disclaimer: ця стаття НЕ є науково-популярною і НЕ роз’яснює наукових фактів ані з соціології, ані з математики. Хоча про першу можна подумати лише прочитавши заголовок, а про другу я багато згадую в тексті. Цей текст не про наукові відповіді, а радше про каверзні питання і про те, як математика може вказати на їхню доречність. Наведені розподіли справжні, і ви можете намагатися повторити цей аналіз вдома — в нашій країні це безпечно.
У нашому суспільстві часто доводиться чути, що математику знати не обов’язково, адже вона “в житті не знадобиться”. Ці міфи безпідставні та шкідливі. Тому я протягом останнього часу написав кілька статей, що пояснюють базові математичні поняття. Для кращого розуміння того, що буде в цій статті, раджу звернути увагу на мою статтю про статистику. Кілька разів я писав, що математика є універсальною і її можна застосувати в багатьох царинах. Сьогодні ми спробуємо застосувати її в політиці, на прикладі теми, цікавої для багатьох – виборів президента України.
Про що розкажуть розподіли?
Все що відбувається в природі чи в суспільстві може бути або випадковим, або мати певну причину (навіть якщо ми її не знаємо). Якщо якийсь процес повторюється багато разів за однакових або майже однакових умов, то різниця між цими повторами має випадковий характер. І в природі, і в суспільстві випадкові процеси відбуваються згідно норма́льного розпо́ділу. Пояснення, чому цей розподіл такий важливий, можна знайти, наприклад, тут.
Якщо, наприклад, ми ловимо перехожих на вулиці, вимірюємо їхній зріст і записуємо, скільки людей має зріст в конкретному інтервалі, то отримаємо гістограму, що буде схожа на цей розподіл. Чим більшу кількість людей ми поміряємо, тим більша буде ця схожість. Коли ловити не всіх перехожих, а лише тих, хто йде в одному напрямку, тоді форма нашого розподілу не зміниться. Чому так відбувається? Тому що те, куди йде людина, визначається не її зростом, а іншими чинниками, з ним не пов’язаними. Якщо ж на досліджуваний процес впливає щось крім випадку, тоді ми отримаємо розподіл іншої форми.
Про що нам скаже форма розподілу? В цьому відео є приклад порівняння розподілів балів у ЗНО та атестатах. Розподіл балів ЗНО там є дуже близьким до нормального, а розподіл балів в атестатах — асиметричний і має “зубці”.
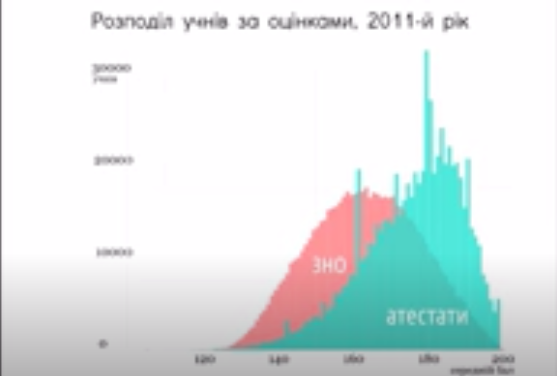
Поясненням такої форми розподілу є невипадковість відмінностей балів в атестатах, а автори матеріалу знаходять пояснення в тому, що вчителі схильні “дотягувати” підсумкові оцінки до “гарної” цифри. Звісно, ніхто жодного вчителя не “впіймав за руку”, і не це було задачею дослідників.
Якщо ми нікого не впіймали, то нащо нам ці розподіли? Якби я навіть не знав, що відбувається в українських школах, і не розумів, що таке “дотягування балів”, але переді мною стояла задача, швидко оцінювати випускників 2011 року, я би скоріше орієнтувався на їхні бали ЗНО. Мені за балом конкретної людини було би легко зрозуміти, наскільки багато його однолітків мали вищий бал, а скільки — нижчий. А розподіл балів з атестатів вказує мені на те, що на цей бал впливають інші невипадкові фактори, яких я не знаю, не розумію і навіть не можу сказати, наскільки сильно вони вплинули на кожну людину. Я би міг припустити, що ЗНО за деяких обставин доцільно використовувати як метрику “обізнаності” випускника 2011 року (ну й інших років за наявності моніторингу і таких самих його результатів). Бал атестату, натомість, я би не сприймав як число, яке може про щось сказати. Це і є та проста задача, до якої допустимо підходити “з однією математикою в руках” в незнайомій області.
Проведу аналогію: коли в магазині ми бачимо на ковбасі плісняву, то це — брак. Можна вже не шукати її склад та термін придатності, не встановлювати видову приналежність грибку плісняви — це не впливає на оцінку товару. Звісно, бувають такі сири, на яких певний вид плісняви повинен бути. Про це варто знати. Однак для більшості продуктів наявність плісняви – неприпустима.
Чи можливо в такий самий спосіб оцінювати “якість” виборів? Я спробував це перевірити, користуючись даними з сайту ЦВК. Я скористався методом аналізу, який вже використовували до мене. Наприклад, тут, тут, тут, тут і тут (матеріали іноземними мовами). Ніхто з цих математиків не претендує на започаткування “виборчої криміналістики”, а лише пропонують цей метод як потенційний індикатор порушень. З огляду на це, з самого початку зазначу, що якщо я знайду щось “підозріле” в результатах голосувань, це буде підставою не для звинувачення, а для запитання до тогочасних політиків: Що ж такого сталося дивного, що розподіли виглядають саме так? І якщо якийсь аудитор буде говорити про “аномальні розподіли політичних преференцій”, йому треба бути дуже переконливим, щоб в це повірили. А якщо аудитора не буде? Питання, що залишилися без відповіді теж мають значення.
Що аналізувати?
Для аналізу потрібен список всіх виборчих дільниць, і для кожної — явка та кількості голосів за кандидатів. Дільниць в країні багато, можна аналізувати розподіли досить детально. Якщо вибори пройшли прозоро (тобто немає незрозумілих чинників), тоді різниця між окремими дільницями матиме випадковий характер, і розподіл явки на дільницях буде нормальним. Точніше близьким до нього, бо є невеличка різниця обумовлена тим, що явка принципово не може бути менше нуля чи більше 100%. Розподіл голосів за явкою на дільницях теж буде близьким до нормального. А якщо політичні погляди в країні більш-менш однорідні, то й форма розподілу голосів за кожного кандидата буде однаковою (тільки висота різна).
Як будується розподіл голосів за явкою? Весь можливий інтервал явки (від 0 до 100%) ділиться на відрізки однакової довжини (в мене – 1%). Ці відрізки називаються бі́нами. Голоси за кандидата, залишені на дільницях, де явка потрапляє в певний бін, додаються і відкладаються на графіку по вертикалі. Окрім цього ми будемо дивитися на двовимірні розподіли дільниць: по горизонталі — явка, по вертикалі — відсоток голосів за досліджуваного кандидата, а колір показує кількість дільниць. Підозрілі аномалії на розподілах я буду називати “артефактами” а те, на що вони можливо вказують — “підозріла активність” або “підозрілі дії”. Але нагадаю, цей аналіз нікого “за руку” не ловить.
Зеленський – Порошенко (2019)
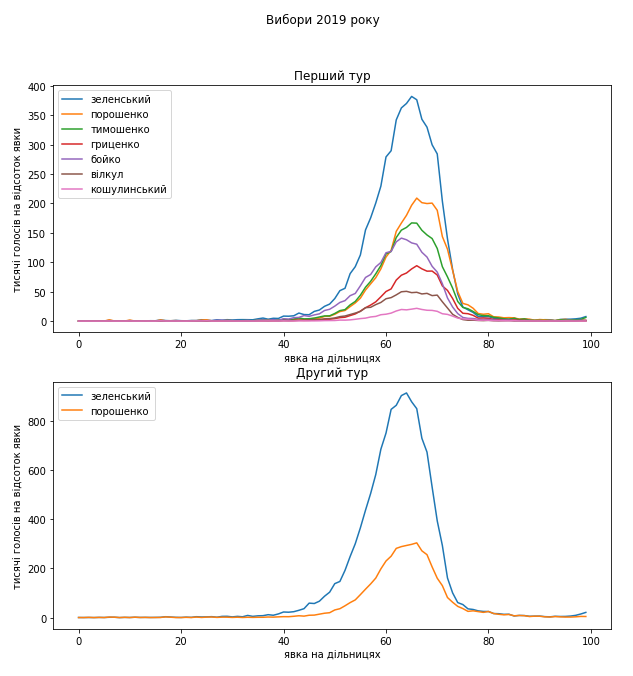
На розподілах голосів під час останніх виборів бачимо гарні піки. Для всіх кандидатів положення піків близьке до середньої явки. Незначну різницю в їхніх положеннях можна пояснити тим, що підтримка принаймні деяких кандидатів може бути неоднорідною по всій країні. Люди це вже аналізували, можете подивитися. Суттєвих аномалій на розподілах не видно. Зверніть увагу, наскільки крутими є схили піків на розподілах голосів. Особливо важливі для нас круті праві схили, оскільки вкиди голосів, якщо вони є, повинно бути видно саме по довгих і викривлених правих схилах цих розподілів.
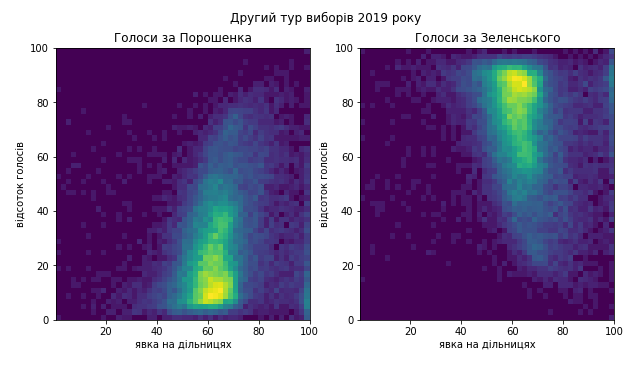
На двовимірних розподілах бачимо піки, вузькі по горизонталі, але розтягнуті по вертикалі. На кожному розподілі голосів лише одне скупчення, це важливо. Жодних артефактів, що вказували би на підозрілу активність ми не бачимо. Можна вважати ці вибори прозорими.
Перемога Порошенка 2014
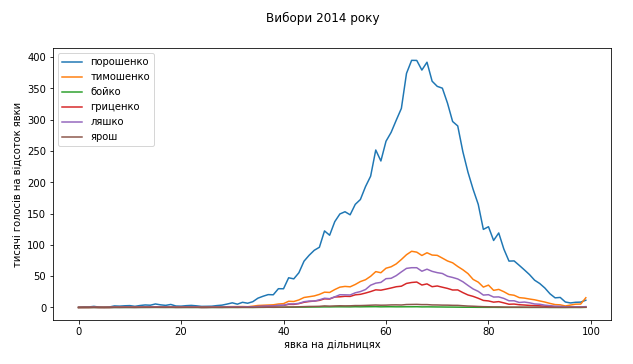
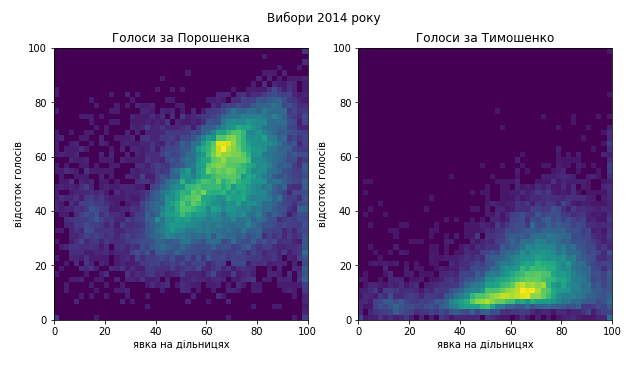
В 2014 році піки на розподілах голосів так само знаходиться на явці між 60% та 70%, але суттєво ширші. Попри це їхні положення й ширини дуже добре збігаються. Підробити це під час фальсифікацій украй важко. На двовимірних розподілах також немає нічого підозрілого. Ширший розкид явки в той важкий для країни рік може мати багато пояснень.
Янукович – Тимошенко (2010)
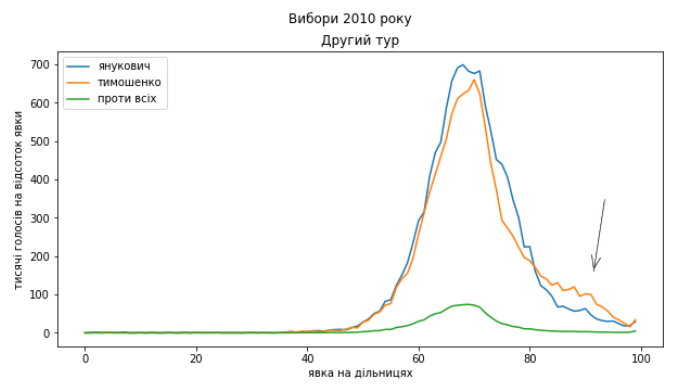
А от у другому турі виборів 2010 року, судячи з викривлених розподілів голосів за кандидатів ми можемо побачити щось цікаве. Це видно по тому, що праві схили піків на розподілах не спадають так, як голоси проти всіх (останній “кандидат” зручний тим, що в ньому ніхто не зацікавлений). Також впадає в око, що ці схили розподілу сильно “пошарпані”. Ось тут обговорюється можливість бачити “накручування” явки чи відсотка голосів до круглих значень в розподілах (матеріал іноземною мовою). Автори стверджують, що коли таке відбувається, видно шерег маленьких піків через кожні 5% чи 10% явки. Але вони працювали з даними по країні, де є “вертикаль”, а в нас все може бути складніше.
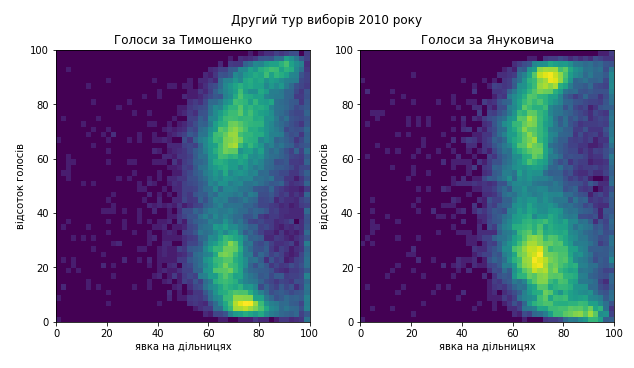
Двовимірні розподіли виглядають дуже дивно. Важко сказати, що могло відбуватися. Бачимо багато скупчень. Подивимося на результати голосування по регіонах окремо. Причину дивних розподілів можна шукати не тільки у фальсифікаціях, але й, наприклад, у територіальній неоднорідності електорату. Ось тут є згадка про випадок впливу неоднорідності електорату у США, який викривив розподіл дільниць за явкою та голосами. Ще ось тут її цитують (матеріали іноземними мовами). Там спостерігали ознаки залежності відсотків голосів від явки на дільниці, але явка на дільницях не досягала 90%-100%, і під час розгляду дільниць з різних регіонів окремо ефект майже зникав.
Давайте подивимось на регіони окремо, щоб зрозуміти картину краще. Стрілочками я показав ті аномалії, які викликають підозри.

Схоже, що в західних областях могла бути підозріла активність на підтримку Юлії Володимирівни. На це вказує виражений “хвіст” на розподілі голосів за явкою і на двовимірному розподілі (як раз вправо вгору). Форма розподілів має деякі відмінності від того, що дослідники спостерігали в РФ і вважали індикатором вкидів. Але відхилення розподілу голосів від нормального настільки значуще, що питання повинні з’явитися.
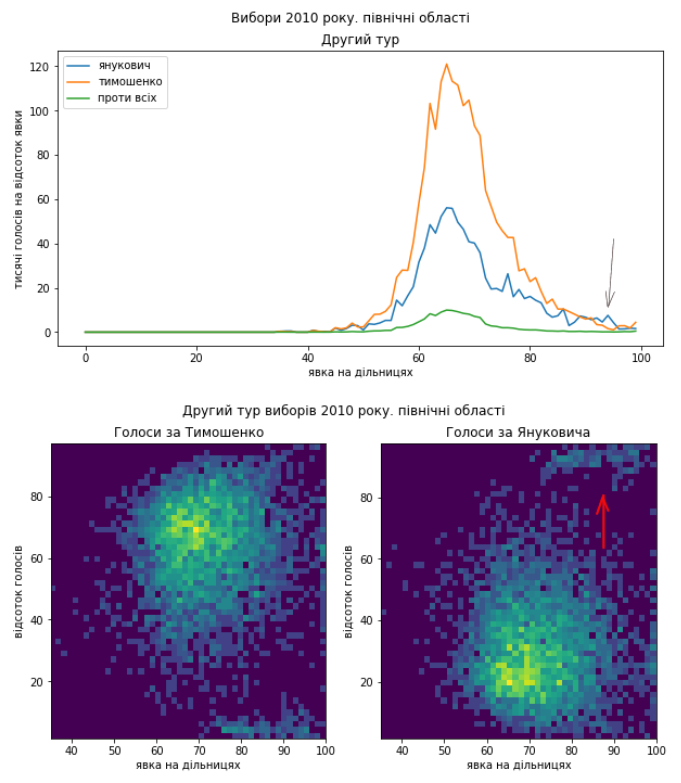
В північних областях бачимо артефакти можливих нечесних дій на користь Януковича на фоні сильної електоральної підтримки Тимошенко. Бачимо аномальний “хвіст” на розподілі голосів за явкою. На двовимірному розподілі ті самі дільниці видно як невелике скупчення далеко поза основним. Таке могло статися, якби більшість дільниць в регіоні діяли чесно, але кілька вдалися до сильних викривлень результатів. Ну або стався такий збіг, що деякі нечисельні групи прибічників Януковича були сусідами і скупчилися в кількох дільницях, витіснивши звідти інших.
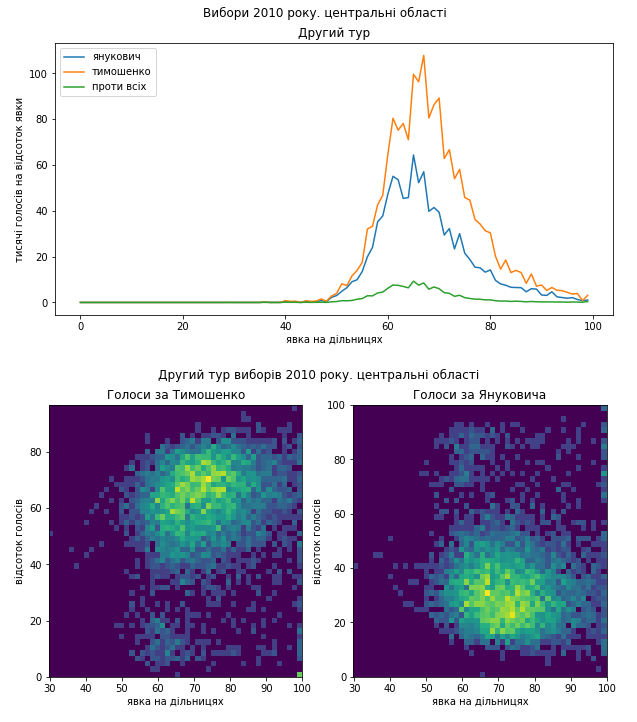
В центральних областях ми бачимо справжню підтримку Юлії Тимошенко на більшості території. Тут підозрілих артефактів не видно. На одновимірному розподілі праві схили піків досить довгі, але мають дуже схожу форму для обох кандидатів. Таку схожість важко підробити.
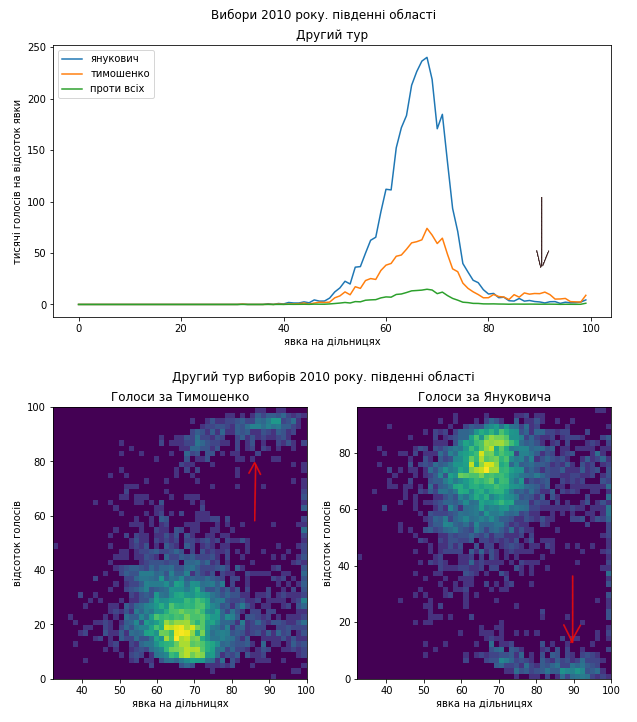
В підвенних областях та АР Крим ми бачимо артефакти, що можуть свідчити про підозрілі дії на користь Тимошенко в умовах сильної електоральної підтримки Януковича. Розподіли є майже дзеркальним відбиттям того, що ми бачили на Півночі.
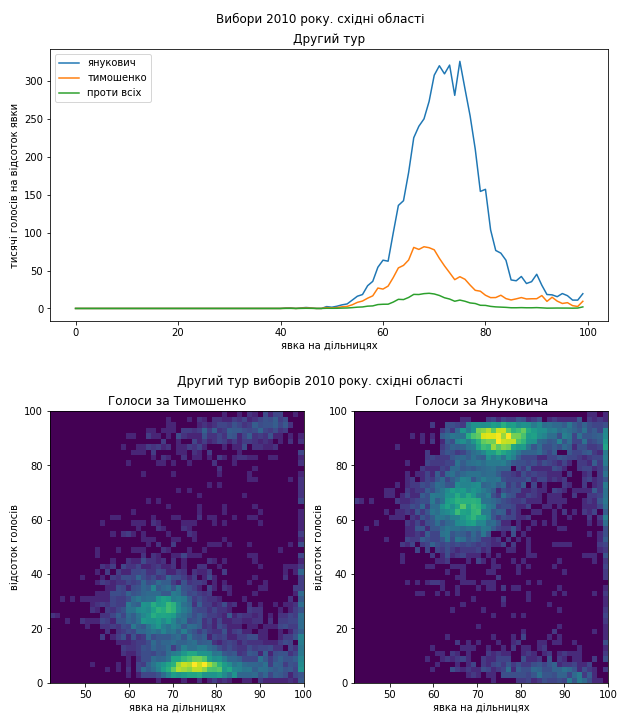
На сході – якась дивна складна картина. Давайте ці області подивимося окремо, щоб перевірити, наскільки сильна тут територіальна неоднорідність.
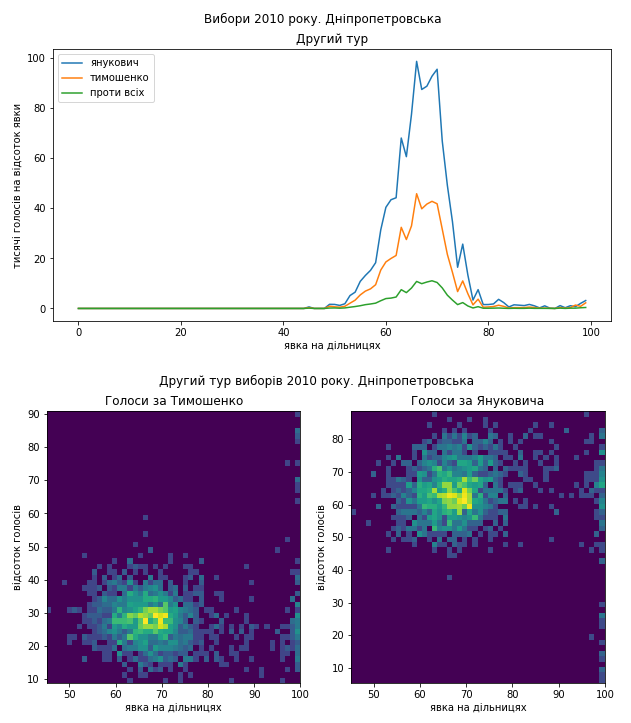
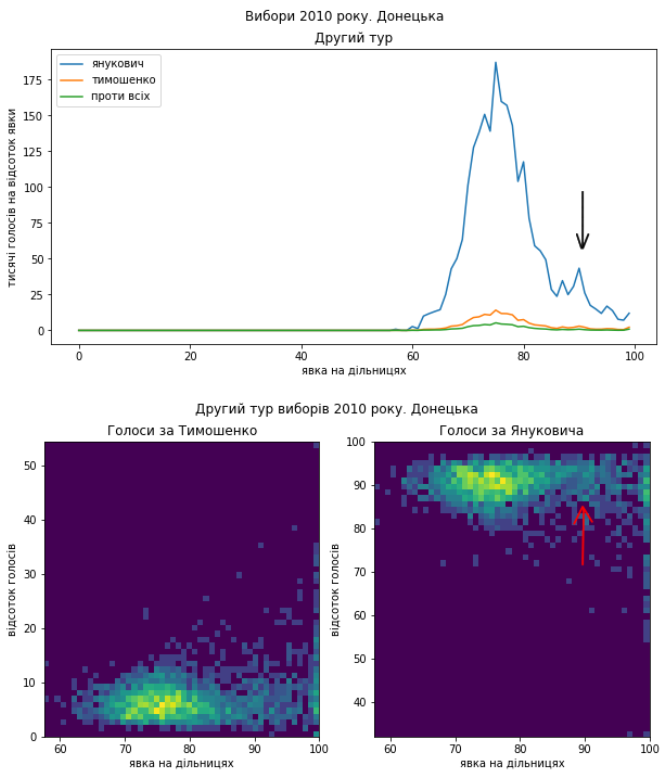
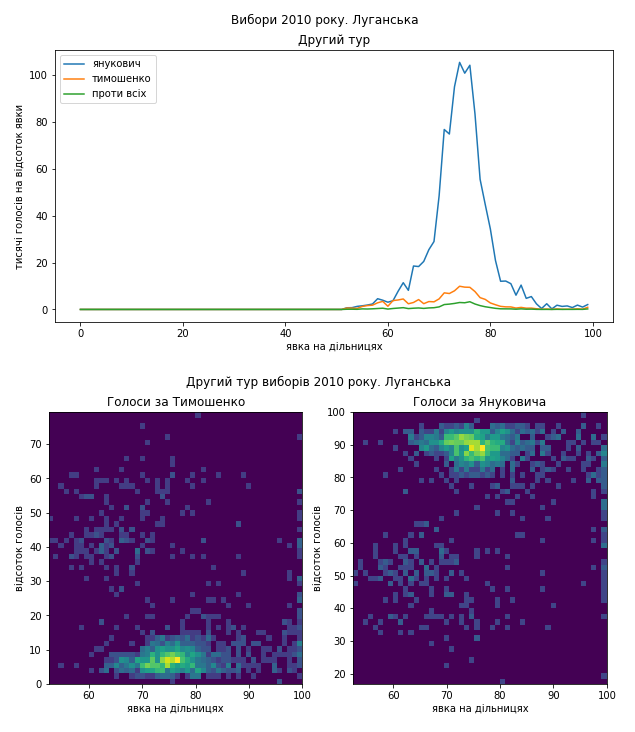
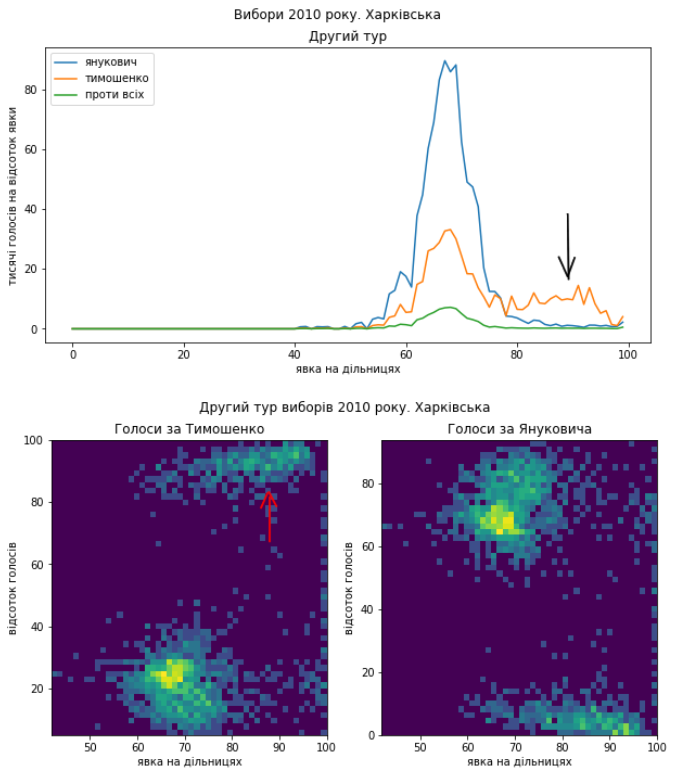
Видно, що в цілому електорат підтримував Януковича, але в Донеччині в розподілі голосів за нього видно виразний “хвіст”, який міг з’явитися в наслідок додаткового “підсилення”. Однак зазначу, що навіть на дільницях з середньою явкою кількість голосів за нього дуже велика. А на Харківщині видно підозріле скупчення голосів на користь Тимошенко.
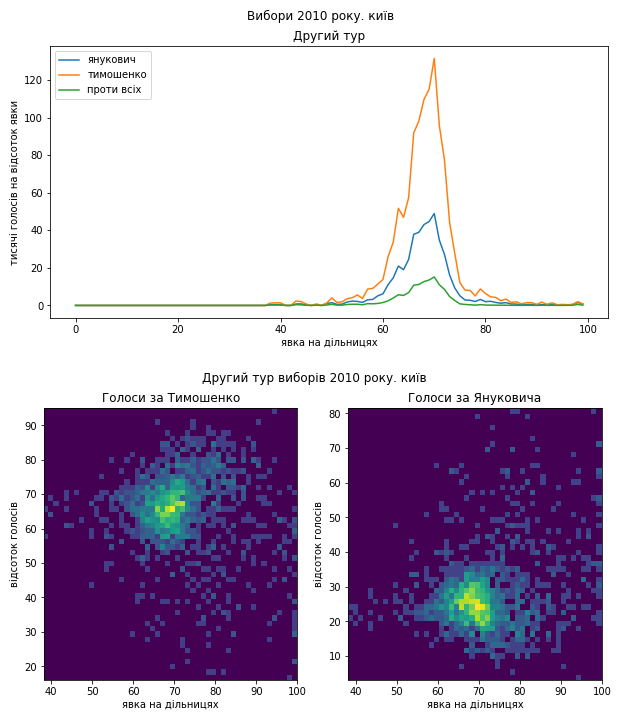
Тим не менш, в Києві ми бачимо “зразково-показові” розподіли голосів. Жодних підозрілих артефактів.
Розподіли голосів на виборах 2010 року викликають в нас дуже багато запитань. Розгляд результатів голосування по різних регіонах окремо дозволив нам побачити досить велику кількість підозрілих аномалій, які не дають нам підстав вважати процедуру голосування прозорою.
Ющенко – Янукович (2004)
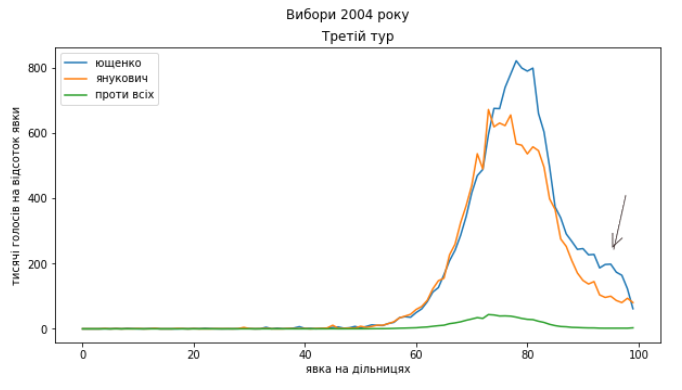
Одразу видно дуже схожі аномалії розподілів голосів по країні. Не зволікаючи перейдемо до розгляду регіонів окремо.
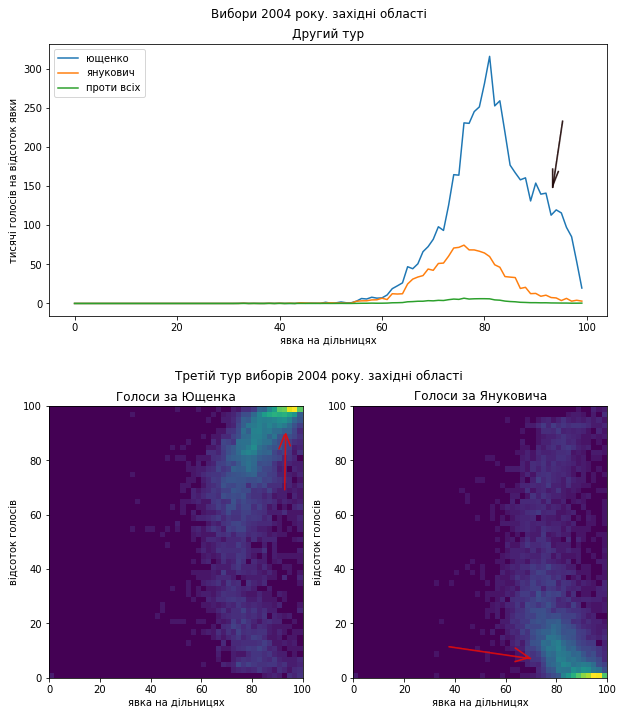
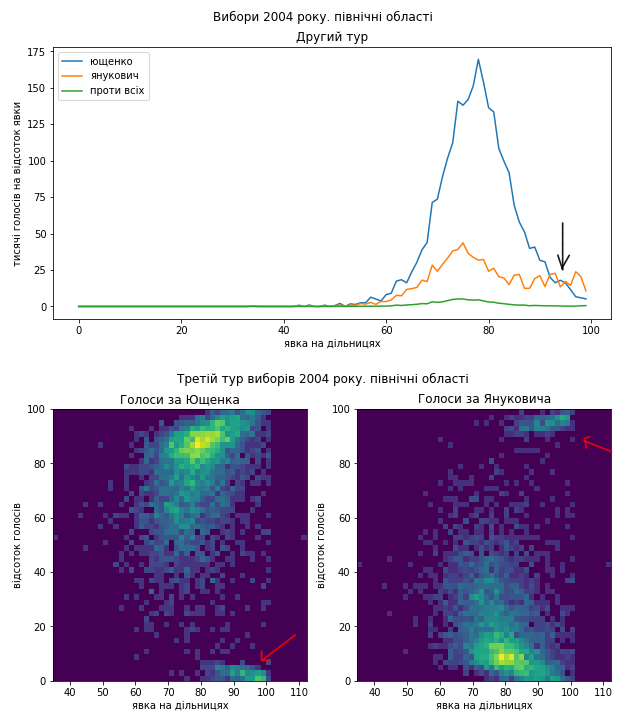
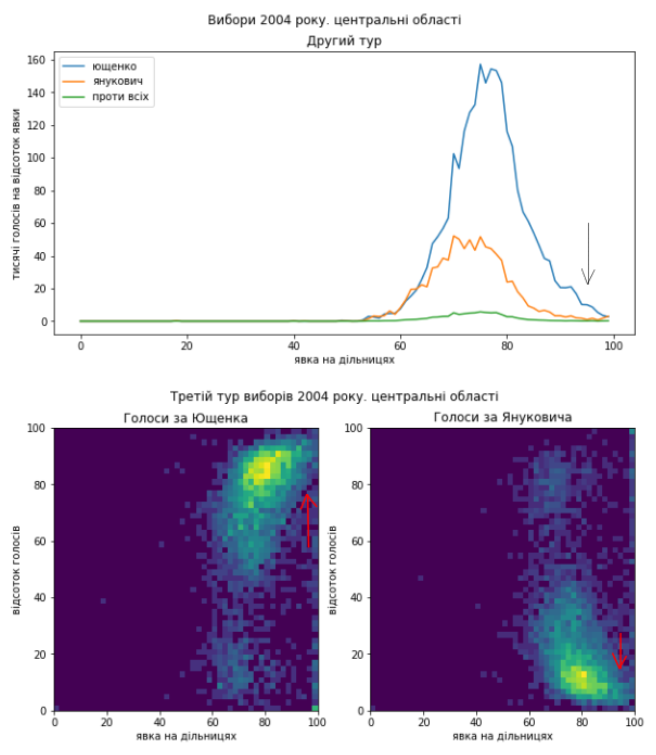
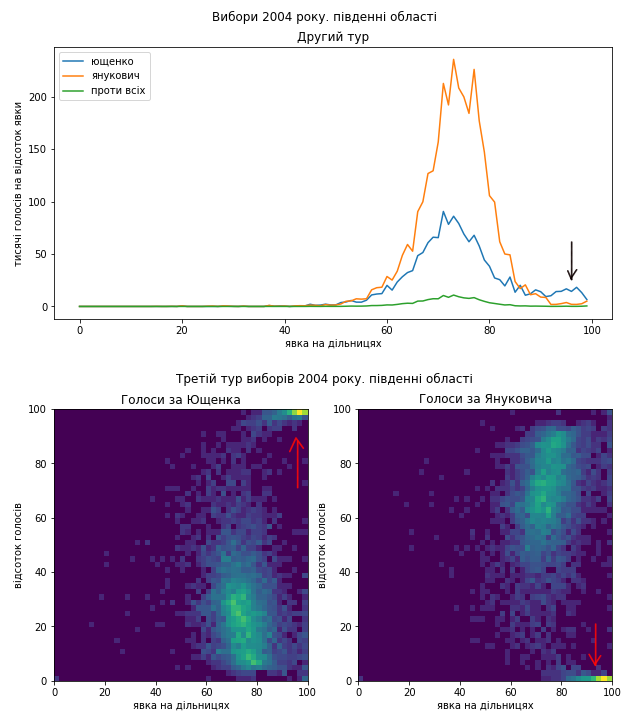
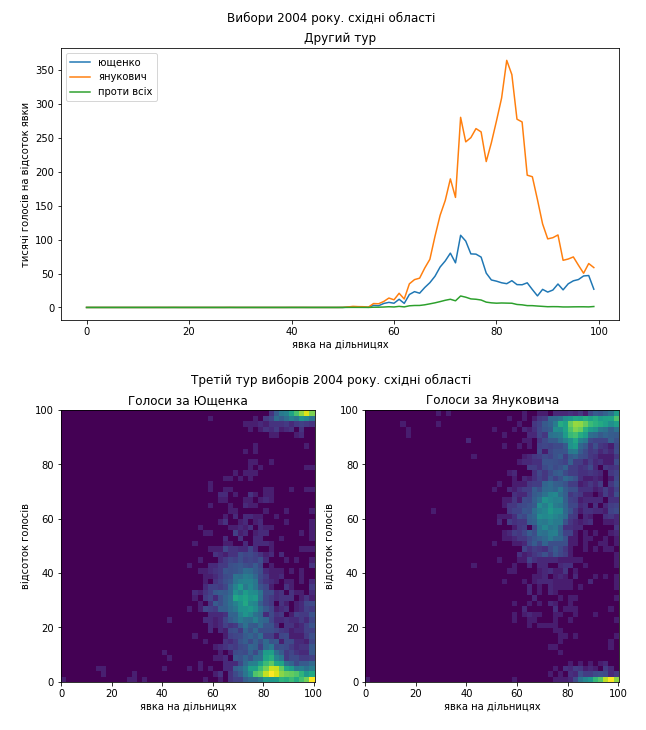
Схід як минулого разу покажемо в деталях:

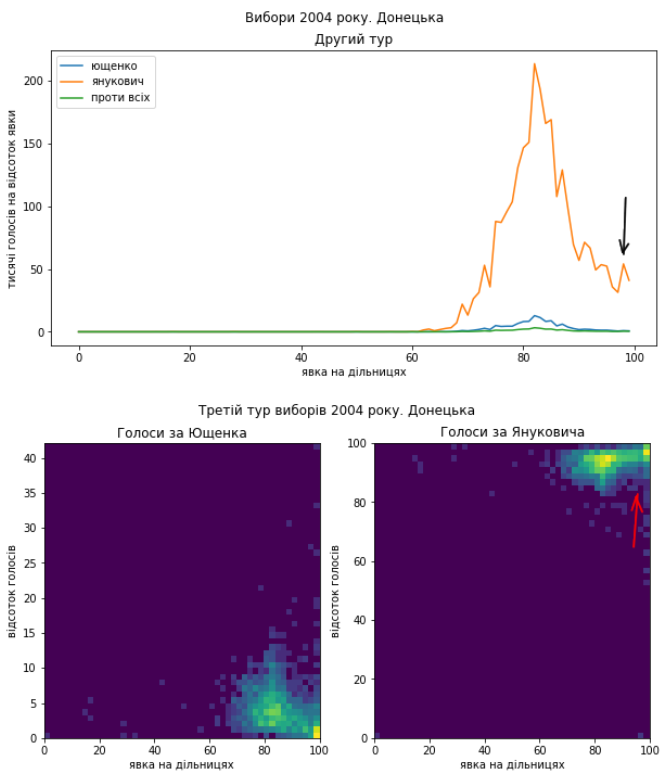
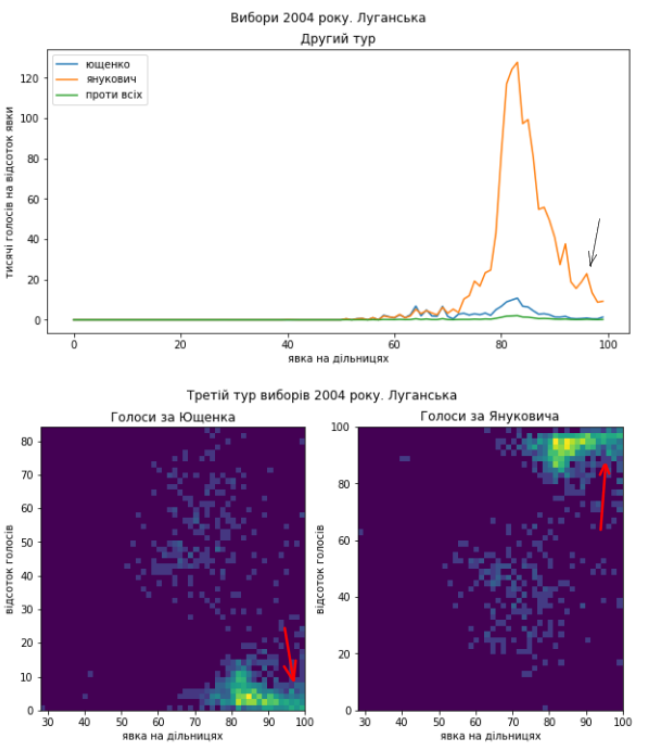
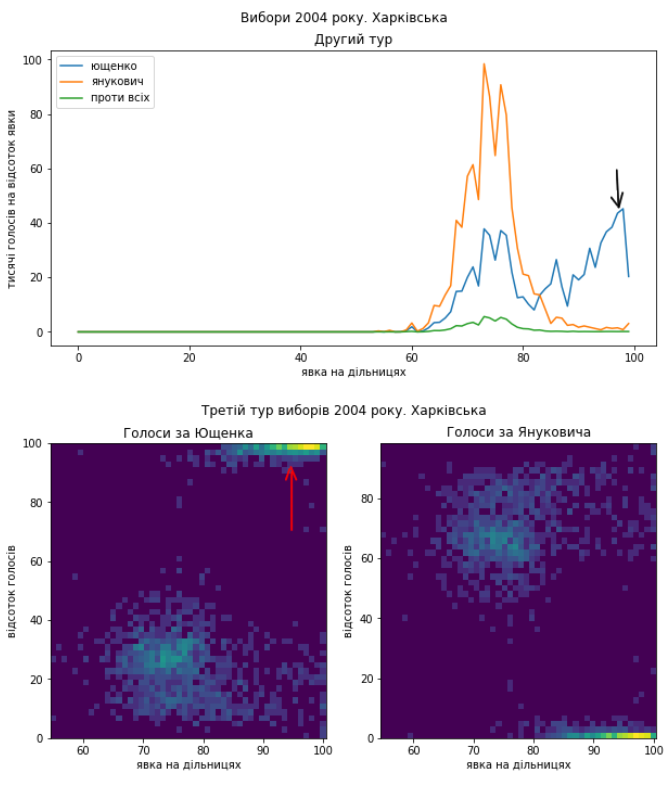
Ну і Київ:
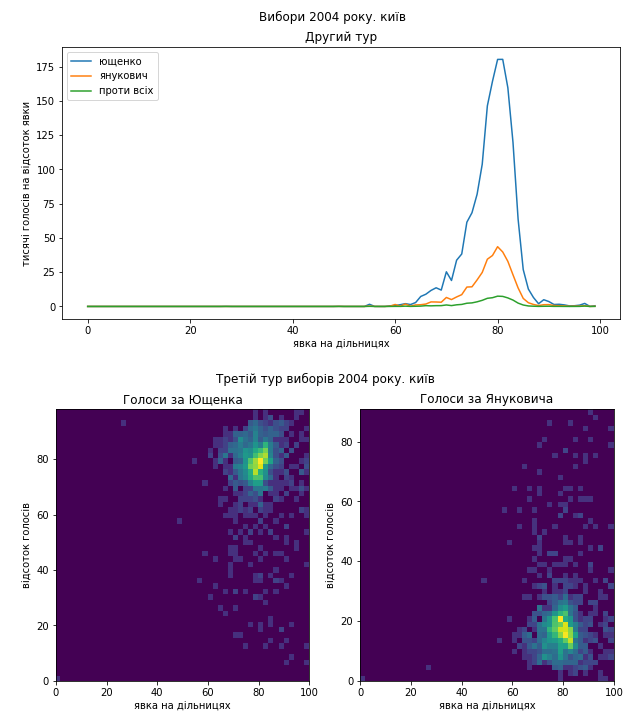
Схоже, що проблеми в голосуванні були такі самі. Я би навіть сказав, що якщо це підозріла діяльність, то схоже, що поділ на “табори” здебільшого зберігся і “почерк” – теж. Тому я не коментуватиму кожний графік окремо, можете порівняти їх з результатами виборів 2010 року самостійно. Скажу коротко, ці вибори я би теж прозорими не назвав.
Кучма – Симоненко (1999)
Для виборів 1999 року сайт ЦВК пропонує веб-відображення інформаційно-аналітичної системи “Вибори президента України”, в якому немає даних про окремі дільниці, є тільки зведені по виборчих округа́х. Цих округів в нашій країні 225 (і ще один – закордонний). Ці дані нам скажуть значно менше, однак це краще ніж нічого.
У порівнянні з кількістю дільниць виборчих округів дуже мало. Чим менша кількість окремих об’єктів в аналізі, тим більший вплив мають флуктуації, тобто цілком випадкове відхилення кількості голосів в одному біні від сусідніх. Через них ми отримаємо “пошарпаний” графік. Ширину біна для розподілів мені довелося збільшити до 4%.
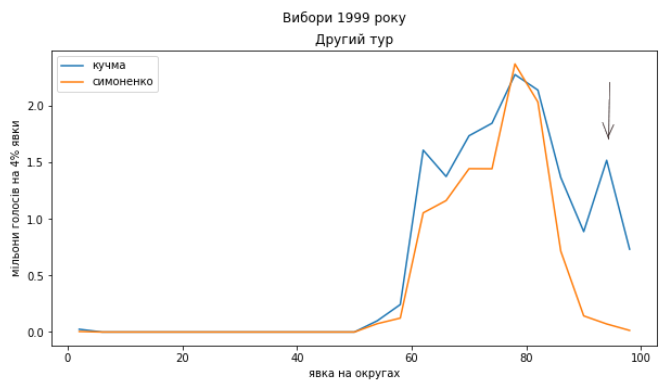
Думаю, попри бідність даних нас повинно насторожити те, що в округах з украй високою явкою (90%-100%) переважна більшість голосів віддана за чинного тоді президента, і дуже мало – за його конкурента. В округах з меншою явкою – зовсім інша пропорція.
Можна було би припустити, що вплинули якісь особливості поділу на округи, але якщо йдеться про їхній розмір, то на меншому окрузі було би менше голосів, отже якась його статистична “ненормальність” не могла би суттєво спотворити загальний розподіл. Натомість “ненормальність” більшого округу скоріш за все має іншу причину ніж просто випадковість. Як бачимо, навіть такі дані вже викликають запитання щодо прозорості голосування.
Детальніше про цей аналіз
Якщо ви бажаєте перевірити мій аналіз більш детально, ось тут ви знайдете код програми для аналізу мовою Python. Дані з виборів 1999 року я приводив у машино-читабельний вигляд вручну, вони теж присутні в репозиторії.
Висновки
Ми побачили, як дані, що ЦВК виклав у відкритий доступ, можна використати для моніторингу. Моє враження таке, що ситуація з прозорістю виборів в нашій країні поступово поліпшується. І важливим переломним моментом, на мою думку, була Революція гідності. Я схильний припускати, що причина в тому, що громадські активісти і незалежні спостерігачі стали активнішими, а можновладці усвідомили можливі наслідки своєї нахабності. Як воно буде далі, залежить не тільки від кількості та активності небайдужих, але й від обізнаності – їхньої та суспільства в цілому.
Аналіз статистичних розподілів не варто розцінювати як стопроцентний доказ наявності чи відсутності фальсифікацій – ми нікого за руку не впіймали. Статистика не досягає такої мети, її задача – моніторинг стану речей. Щоб зробити конкретні висновки, потрібна також правильна інтерпретація отриманих цифр і графіків. А для цього потрібні також знання з предмету досліджень, а отже нам варто було би долучити до дискусії соціологів. Але в будь-якому разі, якщо ми бачимо якісь дивні розподіли голосів, для цього мусить бути причина. Імовірність того, що ми їх отримаємо випадково, вкрай мала. У нас в країні не три дільниці, щоб можна було казати “просто співпало”. І навіть якщо певні артефакти на розподілах голосів можна пояснити територіальною неоднорідністю електоральної поведінки, то варто задуматися, звідки вона походить. Особливо актуальне це питання з огляду на те, що ця неоднорідність сильно зменшилася в 2014 році.
Ось тут ви можете подивитися відео з оглядом минулих виборів у Російській Федерації з 1996 до 2020 років за схожим методом, а тут – статтю з порівнянням останніх виборів президента в нас і в них (Матеріал іноземною мовою). Думаю, це вам теж буде цікаво.
Закінчити цю статтю я хочу закликом до читачів. Цікавтеся математикою, адже вона є досить дієвим критерієм, що вказує, на що слід звернути увагу. Окрім цього варто зберігати здатність бути послідовним і критично мислити без скочування як у легковірність, так і в цинізм. Про шкоду легковірності говорять досить багато. Про цинізм – менше, але я вже писав і розповідав, чому це далеко не найкращий світогляд.
Дні науки

Наші проєкти

Щеплення Правдою



Обговорення