Нуклеїнові ази
13 Липня 2012 | Kseniya Gulak
Категорія: Біологія
ДНК ази
Або що таке є ДНК/РНК, і що можна про них цікавого розповісти
(ні, мова не піде про ДНКази, хехе)
І знов таки на шляху до пояснення епігенетики в мене виникли проблеми. Виявилося, що текст має забагато пояснювань і приміток, цей самий текст наштовханий астерисками і замітками на полях, як бутерброд в дешевому фаст-фуді. Ерго, необхідність створити окремий текст, що нагадає і/або розповість основи молекулярної біології для тих, хто раптом спав в школі (а потім, можливо, і в університеті). Я спробую зробити це узагальнююче-цікавим для тих, хто вже багато-багато знає (хоча би моїми малюночками).
“В дощатом этом балагане вы можете, как в мирозданье, пройти все ярусы подряд, сойти с небес сквозь землю в ад.”
(Так, я частенько це цитую. Але вже занадто він мені подобається, той дядька Фауст).
Зовсім основи

Клітини містять інформацію, яка дозволяє їм функціонувати, рости і розмножуватися. Ця інформація закодована в ДНК послідовності. “Закодована” вона у формі чотирьох нуклеотидів — щось на зразок бінарного коду комп’ютера; але замість 0 і 1 маємо A, T (U), G і C: аденін, тимін (урацил), гуанін і цитозин відповідно.

До речі, можливо комп’ютеру і було б легше і швидше працювати з четвертинним кодом замість бінарного, але технічно без помилок таке зробити важко — що може бути простішим для розуміння для машини, ніж “є/нема сигналу”? Але клітина набагато складніша за комп’ютер, набагато більше вишукана і складна!
Повернімося до теми. Так само, як байт — це найменша адресована одиниця пам’яті ЕОМ, для кодування білків мінімальна обчислювальна одиниця — це триплет, тобто 3 нуклеотиди.
Чому триплет?
Ви це можете пам’ятати ще зі школи. Ми маємо 20 амінокислот, що складають білки, плюс необхідно принаймні ще одна послідовність, яка б виконувала регуляторну функцію, і казала б “Стоп, далі вже не йде білок”. Тому 21 послідовність, закодована 4 різними символами. А тепер згадаймо комбінаторику.
Скільки амінокислот можна було б закодувати за допомогою 4 символів, якщо одному символу відповідає 1 амінокислота? 4^1=4 амінокислоти. Якщо двом послідовним символам відповідає 1 амінокислота? 4^2=16 амінокислот. А от якщо трьом послідовним символам відповідає 1 амінокислота? 4^32=64 амінокислоти — цілком достатньо, для того щоб закодувати існуючі.
До речі, ця ідея прийшла в голову народившомуся в Одесі Джорджу Гамову. Як то кажуть, знай наших!
Як побудована ДНК/РНК?
Стандартна фраза: нуклеїнові кислоти — складні високомолекулярні біополімери, мономерами яких є нуклеотиди, або використаємо аналогію — складний і довгий мур, що складається з великої кількості цеглин. ДНК — мур, нуклеотиди — цеглини. Нуклеотид — це один з тих A, T (U), G і C.

T (U). Ми знаємо, що в молекулі РНК замість тиміну що присутній в ДНК його заміняє урацил. Чому це так? Є теорія, що РНК була так би мовити “першим життям” на планеті — першою молекулою, що здатна до самовідтворення. І лише потім, при переході на більш-менш клітинний рівень життя, функцію “банк інформації” стала виконувати ДНК, як більш стабільна молекула. І підвищення стабільності також відбувалося завдяки зміні У на Т. Також така зміна робить молекулу ДНК легшою для репарації (якщо випадково проходить деамінація цитозину в урацил в молекулі ДНК, такий урацил знову легко замінюється на цитозин [див. гарний малюнок *]).
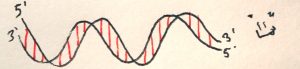
Є ще одна стандартна фраза: ДНК — дволанцюгова молекула. Розшифруємо.
Дволанцюгова молекула і принцип комплементарності
Взагалі то для того, щоб закодувати один білок, необхідна лише одна послідовність нуклеотидів, тобто 1 ланцюг. А чому ж тоді їх два? Ну, на це є проста відповідь і складна. Почнемо з простої — дволанцюгова структура більш стабільна. Складна — тим ланцюгом, що кодує ген, може бути один і другий ланцюг, і крім того є ще багато допоміжних, регуляторних послідовностей, які кодуються в обох ланцюгах (н.п., не кодуючі РНК).
Обидва ланцюги побудовані за принципом комплементарності. Деякі нуклеотиди в одному ланцюгу відповідають іншим нуклеотидам в другому. Аденін — тиміну (чи урацилу), цитозин — гуаніну.
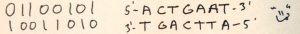
Зробимо приклад знову з бінарним кодом. Якщо б ДНК складалася з 0 і 1 то 1 відповідала б 0, і якщо в одному ланцюжку була б послідовність 001 то до нього б під’єднався би ланцюжок 110 (якщо читати з ліва на право обидва, про напрямок далі).
А чому це саме так? Комплементарність будується завдяки водневим зв’язкам між парами основ. Аденін і тимін можуть сформувати два водневих зв’язки, цитозин і урацил — три. Тому вони і формують відповідно або два або три водневих зв’язки один з одним. Це і є основа комплементарності.

Одним з цікавих висновків з вищесказаного є те, що для розриву А-Т пари треба менше енергії, ніж для розриву C-G пари.
Напрямок
Можна помітити цікаві деталі на малюнку комплементарних пар — один з нуклеотидів в кожній парі “висить догори-дриґом”. Також є дивні позначки — 5′ та 3′ (читається п’ять штрих, три штрих). Це — позначення атомів вуглецю в пентозі (рибозі або дезоксирибозі).
5′ та 3′ кінці молекул нуклеїнових кислот відрізняються один від одного. На 5′ кінці — залишок фосфорної кислоти. На 3′ — OH група.
Найменування й запис в молекулярній біології молекул ДНК/РНК відбувається в 5′ ? 3′ послідовності. І це не від ліхтаря, як то кажуть. В клітині синтез молекули ДНК/РНК відбуваються в такому порядку, бо нова, ще не добудований нуклеотид (нуклеозид трифосфат) містить в собі 3 фосфатні залишки. Було б смішно і енергетично не вигідно намагатись штовхати 3 фосфатні залишки до того кінця молекули, де є ще один.
Чому я кажу “енергетично не вигідно”? Подивіться уважно на молекулу, що під’єднується кожного разу до ДНК.

Це нуклеозид трифосфат. Він вам ні на що не нагадує? А тепер подивіться на молекулу АТФ, — молекулу, що є основним джерелом енергії в реакціях у клітині.

Схожі? Так от, в молекулі АТФ так само як і в нуклеозид трифосфатах міститься енергія у хімічних зв’язках. Процес гідролізу АТФ полягає у відщепленні третього залишку фосфорної кислоти і виділенні енергії. Під час подовження молекули ДНК на один нуклеотид відбувається відщеплення двох залишків фосфорної кислоти. Так, ця реакція виділяє трохи менше енергії ніж така, аби від’єднувався лише один залишок, але все одно енергія виділяється. І це пояснює нам той факт, що для ферментів (ДНК-, РНК-полімераз чи зворотної транскриптази) що синтезують нуклеїнові кислоти, не потрібні окремі АТФ, тобто реакція сама себе забезпечує енергією.
Тепер подивимося на будь-яку послідовність ДНК, наприклад ATTCGGA. Аби не існувало б правила найменування у 5′-3′ напрямку, то можна було б уявити два варіанти двуспіральної ДНК такої послідовності.

І молекули РНК, що зчитуються з неї, можна було б уявити також дві різні: AGGCUUA-3′ та AUUCGGA-3′. А це — зовсім різні молекули, і білки з них — ну, аби вони були трохи довші — зчитувалися би зовсім різні.
Взагалі молекула ДНК ділиться на 2 ланцюги — кодуючий, чи матричний або антизмістовний, — той, з якого береться інформація на побудову РНК (і, оскільки РНК синтез йде у 5′->3′ напрямку, то у якому напрямку йде зчитування ДНК? Правильно, у 3′-5′). Другий ланцюг, комплементарний кодую чому, — змістовний. Його послідовність відповідає послідовності РНК (з заміною T на U, звичайно).
Цікавим є той факт, що поняття матричний/змістовний ланцюги ДНК можуть бути використаними лише в межах одного гена (чи ділянки синтезу нкРНК). Не можна сказати, що в клітині лише одна і повністю вся половина хроматиди — кодуючи, а друга, комплементарна їй, — ні. Вони скачуть і змінюються.

Регуляція всього цього, контроль, виконується багатьма різними чинниками, що взаємодіють з один одним — від внутрішніх, власне ДНК регуляторних послідовностей і модифікацій, до зовнішніх, білкових. Вся ця махінерія управління настільки складна, що лише частині її присвятили окрему гілку — епігенетику, тобто “зверху над генами”. Але це вже потім.
Хмм. Це досить важко визначитися з джерелами. Рекомендую почитати Molecular Biology of the Cell, 4th edition
Дні науки

Наші проєкти

Щеплення Правдою



Обговорення
1 Лютого 2021, 09:24
Доброго ранку, Ксеню. Підкажіть, будь ласка, у вітчизняній генетиці використовують латинські букви від англійських назв нуклеотидів (як у вас тут на всіх картинках) – ACGT, чи все ж кириличні від українських назв – АЦГТ? Дякую наперед за відповідь.
1 Лютого 2021, 16:33
О, це дуже гарне питання.
Якщо ми говоримо про генетиків саме науковців, коли працюєш з генетичним кодом, то тут виключно латинські літери. Всі сервери де зберігаються послідовності нуклеотидів, всі інструменти, а їх дуже багато — від власне приладів для секвенування та різних біоінформатичних застосунків, до табличок активності нуклеаз які ріжуть специфічні послідовності чи послідовностей праймерів для ПЛР реакцій — все це абсолютно виключно в латинському форматі. І нікому і в думку не приходить переводити його в кирилицю. Бо це 1) не потрібно і 2) додаткова складність, операція під час якої може статися помилка 3) важко мати діалог з іншими науковцями з інших країн, бо весь світ використовує лише латинські символи для нуклеотидів — набагато легше мати все в одному форматі.
Якщо вам цікаво детальніше, от гарний стандартний формат FASTA для роботи з нуклеотидними послідовностями. Додам приклад: от так виглядає FASTA ген бета актину людини його мРНК (точніше кДНК, бо всі U у вигляді T, такі кДНК отримують за допомогою зворотної транскрипції, і в основному працюють з ними), а оце його порівняння з геном бета-актину миші та щура (посилання буде активним ще 7 днів, бо сервер має такі властивості). Цима інструментами користуються генетики, молекулярні біологи та біоінформатики з усього світу, який би їхній вітчізняний алфавіт не був.
Але якщо ви візьмете шкільні підручники, то вони чомусь роблять все у кирилиці. Можливо це вимагає МОН, можливо це просто традиція, яку не наважуються перервати. При цьому коли підручники вже не для школярів, а для студентів, то тут питань немає: все знову латинськими символами (наприклад, підручник “Молекулярна біологія”, стор. 66)
Я би не робила такого виключення для школярів. Можливо в більш нових підручниках його і не роблять, бо воно дійсно дивно виходить, і абсолютно не виправдано
1 Лютого 2021, 17:45
Дякую за відповідь. У мене практичний інтерес: перекладаю книжку про генетику. Поки не вирішила, як краще в книжці писати. Якщо автор весь час згадуватиме відповідні азотисті основи, то дивно буде писати їхні назви кирилицею, а кодування – латинкою.
1 Лютого 2021, 18:48
о цікаво)) а що за книга? якщо не секрет 🙂
я б вам дуже радила кодування робити латинкою. Не так вже це і дивно. В хімії це доволі часто буває — кажемо хімічний елемент “Натрій” а пишемо “Na”. Чи навіть деякі білки пишемо “бета актин” а їхній амінокислотний склад “MDDDIAALVV…”, а ген “Actb“. А деякі білки не мають перекладу, і вони і залишаються “Hoxa1” хоча ця частина “hox” має цілком нормальний переклад “гомеобокс” (чи навіть міг би бути “гомеозисний ген a1” але так ніхто не пише, можуть писати “гомеозисний ген Hoxa1” хоча це трохи тавтологія виходить)
А ще дуже класно що перекладачі консультуються! просто взагалі супер.
я вам одразу можу порадити номенклатуру з генетики — як пишуться курсивом назви генів та транскриптів. Напр тут все стисло і зрозуміло.
2 Лютого 2021, 13:06
Книжка ось ця https://www.amazon.co.uk/Genes-That-Make-Us-revolution/dp/1912854368. Дякую за посилання, та мені б мабуть, більше допомогли україномовні наукові ресурси по темі. Я хімік за першою освітою (студенткою навіть трохи підробляла в Інститутів генетики 🙂 ), але тут є складні для мене специфічні речі.
7 Лютого 2021, 11:38
Тоді можу порекомендувати підручник Генетика від КНУ. Він в них висить в pdf на сайті
11 Лютого 2021, 13:31
Дякую, Ксеню. Чи можна вам якось написати в приват, щоб порадитись щодо наукової консультації для перекладу? Напишіть мені на пошту, якщо можна. Дякую наперед. Ось моя ФБ-сторінка https://www.facebook.com/Maryna.Martchenko
Напишіть відгук